T de Transformer
Visión de muy alto nivel de qué hace la T dentro de los modelos GPT.

Desarrollando código desde los 80s desde que en los 80 vi por primera vez un Amstrad en un escaparate de una tienda de electrónica en mi ciudad natal, lo que me llevó a insistirles a mis padres para que me apuntaran a clases de informática donde aprendí cosas como Basic y ensamblador del x86.
A lo largo de mi carrera profesional he pasado por varias revoluciones (y crisis) que han hecho que me haya tenido que ir reinventando para poder seguir desarrollando mi trabajo de la mejor forma posible.
Creo que el desarrollo de software tiene una parte de ciencia pero también una de artesanía (y creatividad) que lo convierten en algo apasionante.
Eternamente contagiado con el Síndrome del Impostor.
Una introducción a los Transformers que se utilizando dentro de GPT y que nos servirá de base para seguirlos estudiando en el resto de artículos de la serie dedicada a la Inteligencia Artificial.
Las siglas GPT vienen de Generative Pre-trained Transformer (GPT) y cada una de ellas se corresponde a cada una de las fases que se llevan a cabo dentro de GTP.
Así G viene de Generative que no son más que una serie de bots que, en el caso de ChatGPT será los encargados de ir generando el texto que se nos irá mostrando
P viene de Pre-trained y lo que hace referencia es al modelo que se construye a través de un proceso de entrenamiento a partir de grandes cantidades de información donde el prefijo pre lo que quiere decir es que estos modelos han de ser entrenados previamente a la utilización de GPT.
T es el Trasformer siendo este quizá la pieza clave de los tres. Tenemos que pensar en un transformer como en un tipo de específico de una red neuronal (un modelo de machine learning) siendo este el aspecto clave que ha hecho que durante los últimos tiempos estemos viviendo un boom en todo lo relacionado con la inteligencia artificial.
Como podemos imaginar existen diferentes tipos de transformers los cuáles se distinguen por la entreda que reciben y la salida que producen (o dicho de otra manera, se distinguen por el modelo que utilizarán). Así nos tendremos:
voice-to-text: un ejemplo serían aquellos modelos que toman como datos de partida un audio y al final lo que acaban produciendo es una transcripción de dicho audio en formato texto.
text-to-voice: otro ejemplo son los transformers que son capaces de producir los sonidos que se producirían como consecuecia de la lectura del texto de entrada.
text-to-image: en este caso el transformer lo que hará será interpretar el texto que recibe como entrada y generar una o más imágenes a partir de dicha interpretación siendo este uno de los aspectos con los que más nos llega a sorprender la IA.
Para encontrar el origen de los transformers tenemos que irnos al año 2017 cuando Google cuando se tuvieron que enfrentar ante el escenario de resolver el problema de transformar un texto que esté escrito en un idioma en el mismo texto pero escrito en un idioma diferente.
chatGPT
Vamos a centrarnos en el caso del transformer que se está utilizando cuando trabajamos con ChatGPT el cual hace uso de un modelo que se está entrenado para a partir de un texto de entrada (que a su vez puede ir acompañado de imágenes, sonidos, etc.) y al finalizar la ejecución del transformer lo que tendremos será una predicción de cuál será el siguiente texto que se mostrará:
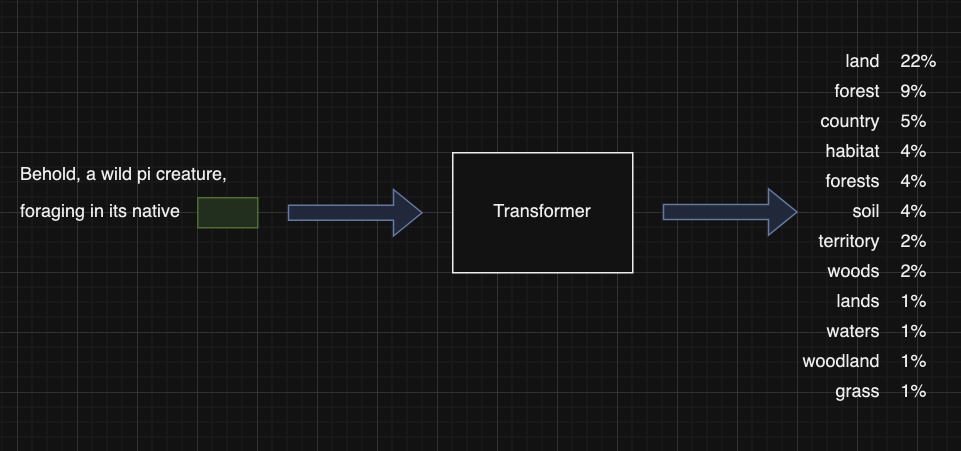
En la imagen anterior se trata de mostrar qué se pretende con el transformer a un alto nivel. Así el transformer estará recibiendo como entrada una frase para la cual se quiere determinar cuál será la siguiente palabra que se la formará y el transformer lo que responsderá será con una serie de palabras y las probabilidades asignadas a cada una de ellas para que continuen la frase (dicho de otra manera, produce una predicción de cuál será la siguiente palabra).
Como se puede ver en la imagen anterior la predicción que produce el transformer no es más que una distribución de probabilidad entre un conjunto limitado de palabras. De hecho, si lo pensamos un poco, podemos llegar a la conclusión de que la obtención de una distribución de probabilidad entre varias palabras y la generación de un nuevo texto a partir de esta predicción pueden parecer dos cosas bastante distintas pero tenemos que pensar en la forma en la que se continuará utilizando el transformer puesto que la inclusión de la palabra predecida se añadirá al texto de entrada que se le ha pasado y se obtendrá una nueva predicción que se añadirá al texto de entrada continuando el proceso hasta que se obtenga un texto final.
Así un modelo como GTP 2 lo podemos utilizar para que nos genere una historia de la siguiente manera:
Le proporcionaremos un texto semilla (seed) que es la base con la que se construirá la historia.
El transforme recibe es base y nos generará la predicción de las siguientes palabras con su distribución de probabilidad.
GTP2 determinará cuál de ellas se debe elegir (una forma de hacerlo sería de manera random pero siempre atendiendo a la probabilidad que tienen cada una de estas palabras).
Se añade la palabra seleccionada al final del texto seed para que se el nuevo texto a partir del cual generar la distribución de probabilidad.
Se pasan a repetir los pasos 2 al 4 hasta que GPT2 determine que ya no se pueden añadir más palabras.
Como podemos imaginarnos el función de la evolución del transformer que estemos utilizando la historia que iremos obteniendo puede o no tener más o menos sentido porque con GPT2 es probable que no parezca muy bien escrita pero al pasar a un modelo como GPT3 (que básicamente es el mismo modelo que GPT2 pero avanzado) es más que probable que la historia pase a tener mucho más sentido.
Por lo tanto este proceso que acabamos de describir es que el ocurre en todos los modelos LLM (Large Languages Models) que han sido construidos con el fin de que puedan proporcionar una palabra en cada instante de tiempo.




